How to Build an Automated AI Blogging System
Checkout the GitHub Repository
https://github.com/taskautomation/blog-python-ai
Okay, so I have set up a simple blog using Jekyll and GitHub Pages, but not I want to start making content. I have heard a lot of buzz about that AI can do all the content creation for you, but how can you do that yourself? That is what I will show you in this article.
Let's build on the Jekyll project I linked to above and start by creating a new project folder in the same parent folder as the Jekyll blog. If you prefer you can also just clone the repository from GitHub.
mkdir blog-python-ai
This is what the folder structure will look like from the parent folder (called Jekyll):
├───blog-python-ai
└───jekyll-ai-blog
├───css
├───_includes
├───_layouts
├───_posts
└───_sass
I could create a new blog post by prompting ChatGPT create the content, copy it into a markdown file, add commit and push the the jekyll-ai-blog repository. But this is too manual. I want to automate this process, and I want the AI to know that this is the process with multiple steps, and do them for me. I just want to give it some minor instructions, and let it do the rest. There are many ways to accomplish this. For example creating a chain where the first step is prompting an llm to create the content, mechanically pipe it into a markdown file, and automate the commit and push it to the repository. But in this post I will be creating an agent, that uses tools in order to accomplish this. It feels more like a real autonomous assistant or employee, it's more fun and easier to expand on. This could also be done in a more advanced and production ready way with LangGraph, but the setup is more work.
I will be using OpenAIs GPT-4o (you need an API key for this, create one here) and LangChain (python), which is a framework for LLM applications.
Environment Setup
Lets move into our project folder and create a new virtual environment:
cd blog-python-ai
python -m venv .venv
.\.venv\Scripts\Activate
Install the required packages:
pip install langchain langchain-core langchain-openai langchain-community
If you want to run in a notebook environment you also have to install ipykernel:
pip install ipykernel
The Agent
The basic steps to setting this up are the following:
- Set up the LLM
- Set up the necessary tools
- Tie them together with the LLM in an agent
- Write a prompt for the specific task at hand
- Run the prompt through the agent
Lets start by setting up the LLM. I will be using OpenAIs GPT-4o for this. You can use any LLM you want, but you have to adjust the code (and prompt) accordingly. I have my OpenAI API key stored in an environment variable called OPENAI_API_KEY. You can also pass it in directly to the ChatOpenAI class.
Setting up the LLM
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="gpt-4o",
temperature=0,
max_tokens=None,
timeout=None,
max_retries=2,
)
Creating and importing the tools
Next up is creating the tools. The agent need access to the file system in order to create blog posts as mark down files, and potentially read the existing posts in order to avoid creating too similar posts. This tool we do not have to create ourselves, we can use the FileManagementToolkit toolkit from LangChain. In this toolkit there are tools for reading, writing, listing and moving files, which is all we need for this task. In this step I also change directory to the jekyll blog folder, as this is where the blog posts will be created.
from langchain.agents.agent_toolkits import FileManagementToolkit
import os
# Load tile management toolkit
toolkit = FileManagementToolkit(
selected_tools=["write_file", "list_directory", "read_file"],
)
# Set working directory to your Jekyll blog directory
os.chdir('C:\\Users\\fredr\jekyll\\jekyll-ai-blog\\')
The rest of the tools are simple home made tools for performing git commands through the command line with the subprocess module in python and fetching the current date. To create custom tools we also need to import the tool decorator from LangChain. There are many ways of creating custom tools in langchain, but this is the simplest way, if you have an uncomplicated task to complete, like the ones we have in this case.
The tools are functions which passes one argument each to a predefined git command. The tool decorator makes the function available to the agent.
- git add requires a
file path - git commit requires a
message - git push requires a
branch name
There is also a description of what the tools do which is useful for the agent to know what the tools do.
from langchain.tools import tool
import subprocess
# Define git helper functions
@tool
def git_add(file_path="."):
"""Adds file(s) to the staging area."""
subprocess.check_call(["git", "add", file_path])
@tool
def git_commit(message):
"""Commits the changes with a given message."""
subprocess.check_call(["git", "commit", "-m", message])
@tool
def git_push(branch_name="gh-pages"):
"""Pushes the committed changes to a specified remote and branch."""
subprocess.check_call(["git", "push", "origin", branch_name])
The last home made tool is a function that fetches the current date. This is useful for the agent as it is needed in the front matter of the markdown file.
from datetime import datetime
@tool
def get_date(arg='today'):
"""Returns the current date as a string."""
now = datetime.now()
return now.strftime("%Y-%m-%d")
The following code adds all the tools to a list of tools which will be passed to the agent.
# Home made tools
tools = [
git_add, git_commit, git_push, get_date
]
# Add the file system toolkit tools
tools += toolkit.get_tools()
Creating the agent
The next step is to create the agent. Let's start with a prompt template and write a system prompt to guide the agent. The agent also need a scratchpad to keep track of it's steps and reasoning.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are very powerful assistant, skilled at writing engaging blog posts and using the provided tools.",
),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
Binding the tools to the LLM is a way of converting the functions into tools and passing them to the model on every invocation.
llm_with_tools = llm.bind_tools(tools)
With two more utility functions from langchain for formatting intermediate steps and a component that parses a message into agent finish. This is chained together with the prompt and the LLM with tools with the Langchain Expression Language syntax.
from langchain.agents.format_scratchpad.openai_tools import (
format_to_openai_tool_messages,
)
from langchain.agents.output_parsers.openai_tools import OpenAIToolsAgentOutputParser
agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_to_openai_tool_messages(
x["intermediate_steps"]
),
}
| prompt
| llm_with_tools
| OpenAIToolsAgentOutputParser()
)
Just a few more steps. Create the agent executor..
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
Writing the prompt
.. and write a suitable prompt. For me this was a matter of trying and failing, some times I justed added specific parts to avoid certain behaviour, and other parts are just trying to force or encourage some other behaviour. This is my prompt, trying to make it create content for an audience of marketers that wants to learn about practical statistical concepts.
query = """
You are an AI assistant with great technical knowledge that writes technical blog posts about implementing specific techniques in python.
You are an AI assistant with great knowledge about marketing and statistics that writes blog posts about practical statistical concepts for marketers.
You will be building a blog with a series of blog posts, which can be found in the _posts folder.
It is a Jekyll blog hosted with GitHub pages. When I new post is commited and pushed to the gh-pages branch, it will be published on the blog.
Focus on writing helpful and engaging posts, like how-to posts, can increase the usefulness of the blog.
Always include code to illustrate techniques.
Avoid generic content/posts and buzz word content.
Then write the blog post and save it in the _posts folder as a markdown file with a suitable name.
Use the get date tool to get the current date, which you need for the blog post.
The new blog post should increase the usefulness of the blog so that you can get more readers and build a broader audience.
Do not: write a blog post about exactly the same topic as an existing blog post.
Do not: write a blog post about a topic that is totally unrelated to the existing blog posts.
Do not: write a blog post that is a slight variation of a previous blog post.
The blog post should be structured as follows:
A blog post always starts with a title, followed by a date (use get date tool), followed by category, followed by the actual blog post.
-----
Example:
Title: Getting started with Jekyll
Date: 2024-08-26
Category: Blog
etc.
-----
Always remember to use the write_file tool to write the blog post to the _posts folder as a markdown file.
Write a new blog post with at least 1500 words.
Afterwards, use the provided tools to git add, commit and push (gh-pages branch) the new file to the github repository.
"""
Running the agent
Let's give it a run.
agent_executor.invoke({"input": query})
This was the steps and output from the run (I removed most of the actual blog post, but you can find it here)
> Entering new AgentExecutor chain...
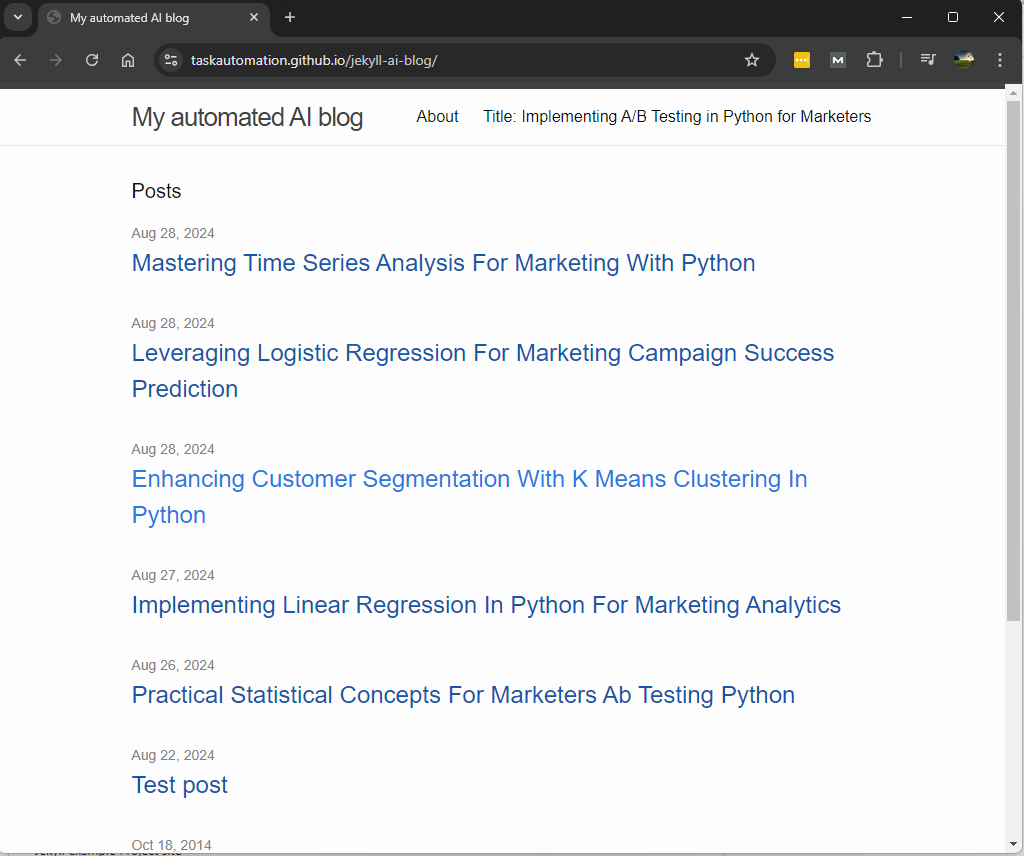
Invoking: `list_directory` with `{'dir_path': '_posts'}`
2014-10-18-welcome-to-jekyll.markdown
2024-08-22-test-post.md
2024-08-26-practical-statistical-concepts-for-marketers-ab-testing-python.md
2024-08-27-implementing-linear-regression-in-python-for-marketing-analytics.md
2024-08-28-enhancing-customer-segmentation-with-k-means-clustering-in-python.md
2024-08-28-mastering-time-series-analysis-for-marketing-with-python.md
Invoking: `get_date` with `{}`
2024-08-28
Invoking: `write_file` with `{'file_path': '_posts/2024-08-28-leveraging-logistic-regression-for-marketing-campaign-success-prediction.md', 'text': "### Title: Leveraging Logistic Regression for Marketing Campaign Success Prediction\n\n### Date: 2024-08-28\n\n### Category: Marketing Analytics\n\n---\n\nIn the realm of marketing, predicting the success of a campaign can significantly enhance decision-making and resource allocation. One powerful statistical technique that can be employed for this purpose is Logistic Regression. This blog post will guide you through the process of implementing Logistic Regression in Python to predict the success of marketing campaigns.\n\n#### What is Logistic Regression?\n\nLogistic Regression is a statistical method for analyzing datasets in which there are one or more independent variables that determine an outcome. The outcome is measured with a dichotomous variable (in which there are only two possible outcomes). In marketing, these outcomes could be whether a customer will respond to a campaign or not.\n\n#### Why Use Logistic Regression in Marketing?\n\n1. **Binary Outcomes**: Logistic Regression is ideal for binary outcomes, such as predicting whether a customer will buy a product (yes/no).\n2. **Probabilistic Interpretation**: It provides probabilities for the outcomes, which can be useful for risk assessment.\n3. **Feature Importance**: It helps in understanding the importance of different features in predicting the outcome.\n\n#### Step-by-Step Guide to Implementing Logistic Regression in Python\n\n##### Step 1: Import Necessary Libraries\n\nFirst, we need to import the necessary libraries. We will use `pandas` for data manipulation, `numpy` for numerical operations, and `sklearn` for implementing Logistic Regression.\n\n```python\nimport pandas as pd\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import accuracy_score, confusion_matrix, classification_report\n```\n\n##### Step 2: Load and Explore the Dataset\n\nFor this example, let's assume we have a dataset named `marketing_campaign.csv` which contains information about various marketing campaigns and their outcomes.\n\n```python\n# Load the dataset\ndata = pd.read_csv('marketing_campaign.csv')\n\n# Display the first few rows of the dataset\nprint(data.head())\n```\n\n##### Step 3: Data Preprocessing\n\nBefore we can use the data for modeling, we need to preprocess it. This includes handling missing values, encoding categorical variables, and splitting the data into training and testing sets.\n\n```python\n# Handle missing values\ndata = data.dropna()\n\n# Encode categorical variables\ndata = pd.get_dummies(data, drop_first=True)\n\n# Split the data into features and target variable\nX = data.drop('campaign_success', axis=1)\ny = data['campaign_success']\n\n# Split the data into training and testing sets\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)\n```\n\n##### Step 4: Train the Logistic Regression Model\n\nNow, we can train the Logistic Regression model using the training data.\n\n```python\n# Initialize the Logistic Regression model\nlogreg = LogisticRegression()\n\n# Train the model\nlogreg.fit(X_train, y_train)\n```\n\n##### Step 5: Make Predictions\n\nAfter training the model, we can use it to make predictions on the test data.\n\n```python\n# Make predictions on the test data\ny_pred = logreg.predict(X_test)\n```\n\n##### Step 6: Evaluate the Model\n\nTo evaluate the performance of the model, we can use metrics such as accuracy, confusion matrix, and classification report.\n\n```python\n# Calculate the accuracy of the model\naccuracy = accuracy_score(y_test, y_pred)\nprint(f'Accuracy: {accuracy}')\n\n# Display the confusion matrix\nconf_matrix = confusion_matrix(y_test, y_pred)\nprint('Confusion Matrix:')\nprint(conf_matrix)\n\n# Display the classification report\nclass_report = classification_report(y_test, y_pred)\nprint('Classification Report:')\nprint(class_report)\n```\n\n##### Step 7: Interpret the Results\n\nThe confusion matrix and classification report provide detailed insights into the performance of the model. The accuracy score gives a general idea of how well the model is performing, but the confusion matrix and classification report provide more granular details such as precision, recall, and F1-score.\n\n#### Practical Example: Predicting Email Campaign Success\n\nLet's consider a practical example where we use Logistic Regression to predict the success of an email marketing campaign. The dataset `email_campaign.csv` contains the following columns:\n\n- `age`: Age of the customer\n- `income`: Income of the customer\n- `previous_purchases`: Number of previous purchases\n- `email_opened`: Whether the email was opened (1 for yes, 0 for no)\n- `clicked_link`: Whether the customer clicked the link in the email (1 for yes, 0 for no)\n- `campaign_success`: Whether the campaign was successful (1 for yes, 0 for no)\n\n```python\n# Load the dataset\nemail_data = pd.read_csv('email_campaign.csv')\n\n# Display the first few rows of the dataset\nprint(email_data.head())\n\n# Handle missing values\nemail_data = email_data.dropna()\n\n# Encode categorical variables\nemail_data = pd.get_dummies(email_data, drop_first=True)\n\n# Split the data into features and target variable\nX_email = email_data.drop('campaign_success', axis=1)\ny_email = email_data['campaign_success']\n\n# Split the data into training and testing sets\nX_train_email, X_test_email, y_train_email, y_test_email = train_test_split(X_email, y_email, test_size=0.3, random_state=42)\n\n# Initialize the Logistic Regression model\nlogreg_email = LogisticRegression()\n\n# Train the model\nlogreg_email.fit(X_train_email, y_train_email)\n\n# Make predictions on the test data\ny_pred_email = logreg_email.predict(X_test_email)\n\n# Calculate the accuracy of the model\naccuracy_email = accuracy_score(y_test_email, y_pred_email)\nprint(f'Accuracy: {accuracy_email}')\n\n# Display the confusion matrix\nconf_matrix_email = confusion_matrix(y_test_email, y_pred_email)\nprint('Confusion Matrix:')\nprint(conf_matrix_email)\n\n# Display the classification report\nclass_report_email = classification_report(y_test_email, y_pred_email)\nprint('Classification Report:')\nprint(class_report_email)\n```\n\n#### Conclusion\n\nLogistic Regression is a powerful tool for predicting binary outcomes, making it highly suitable for marketing applications such as predicting campaign success. By following the steps outlined in this blog post, you can implement Logistic Regression in Python and gain valuable insights into your marketing campaigns. This can help you make data-driven decisions and optimize your marketing strategies for better results.\n\nRemember, the key to successful implementation lies in thorough data preprocessing and careful evaluation of the model's performance. Happy modeling!\n\n---\n\nThis blog post provides a comprehensive guide to implementing Logistic Regression for marketing campaign success prediction. By following the steps and code provided, marketers can leverage this powerful statistical technique to enhance their decision-making processes and achieve better campaign outcomes.\n"}`
responded: ### Title: Leveraging Logistic Regression for Marketing Campaign Success Prediction
### Date: 2024-08-28
### Category: Marketing Analytics
....`I removed the rest of the post`
File written successfully to _posts/2024-08-28-leveraging-logistic-regression-for-marketing-campaign-success-prediction.md.
Invoking: `git_add` with `{'file_path': '_posts/2024-08-28-leveraging-logistic-regression-for-marketing-campaign-success-prediction.md'}`
None
Invoking: `git_commit` with `{'message': 'Add blog post on leveraging logistic regression for marketing campaign success prediction'}`
None
Invoking: `git_push` with `{'branch_name': 'gh-pages'}`
NoneThe new blog post on leveraging logistic regression for marketing campaign success prediction has been successfully added, committed, and pushed to the `gh-pages` branch. It should now be live on the blog. Happy reading!
> Finished chain.
So, it starts by checking the existing blog posts to get a sense of the topics already covered, checks the date and proceeds to write a blog post about logistic regression for marketing campaign success prediction. It then writes the blog post to a markdown file, adds, commits and pushes the file to the repository, and GitHub does the rest.
Next natural step would be to schedule this thing to run regularly, and maybe add some tools such as search engine to do research for the blog posts.
I would love to hear your thoughts on this. Thanks for reading!
Subscribe to my newsletter.
Get updates on my latest articles and tutorials.
- Weekly articles
- I aim to publish new content every week. I will also share interesting articles and tutorials on my blog.
- No spam
- You will not receive any spam emails. I will only send you the content that you are interested in.